Plugin的一个重要的特性就是增加了压缩存储。对于数据中有很多Long column(包括TEXT BLOB或者大VARCHAR)的场景能够大幅节约空间,并提升效率。
1. 谁需要压缩?
在InnoDB中,是以16K的页(Page)为基本的存储单位的。我们知道,InnoDB是的数据是在Clustered index中存储的,在Secondary index中仅存储对应数据的PK。Clustered index和Secondary index都是B-Tree结构的,所以对InnoDB数据页和索引页的压缩很大程度上就是对B-Tree节点页的压缩。
在InnoDB中,除了B-Tree节点页,还有一类数据页(Page),称为“overflow page”。当需要存储Long column时,如果当前页能够完全存储全部字段时,则存储在当前页中;如果当前页不足以存储全部,则InnoDB选择最长的字段,将其存储到一个单独的页中,我们称这样的页为“overflow page”,而原数据页仅仅需存储一个20Bytes的指针。参考下图:
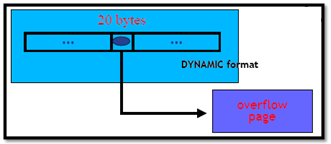
所以InnoDB除了有上面的B-Tree页外,InnoDB还存储overflow页。事实上,需要压缩的数据页也就是这两类,InnoDB为了获得更好的效率,针对这两类数据页的压缩是使用不同的策略的。
2. 如何压缩B-Tree页
未来尽可能多的避免压缩、解压带来的额外消耗,InnoDB在压缩后的B-Tree页中新增了一个modification log区,通过记录当前的页的修改日志,来避免频繁压缩解压(参考左图)。

当modification log空间不足时,才进行解压并应用这些Log,然后再压缩回去。如果必要,这里可能会出现B-Tree页的分裂。
3. 如何压缩over-flow页
overflow的压缩页面则相对简单,仅包含一个页面头(header),页面尾(Trailer)中间就是压缩数据。试想,如果存储的Long Column是能够高度压缩的内容(例如文本,Xml等),这样将节省很多的存储空间,进而能够节省I/O。(参考下图)![]()
4. 压缩的算法是什么
压缩使用的是zlib library中的LZ77算法。
5. 压缩和Buffer Pool
当使用压缩存储的页面,当Buffer Pool载入后,会将其解压。这时,该页面在Buffer Pool中同时存在“压缩版”和“解压版”。当Buffer Pool需要驱逐这些页的时候,有两种情况会发生:如果InnoDB认为当前应用是IO-Bound,相比CPU还有额外能力来做解压操作,则InnoDB选择仅驱逐页面的“解压版”;否则InnoDB会将页面的两个版本同时驱逐出去。也就是说Buffer Pool会是下图的状态:
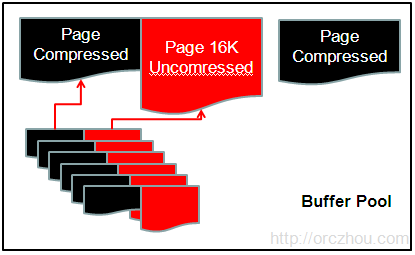
6. 如何创建一个压缩数据表
原理是复杂的,操作其实很简单:
ROW_FORMAT=COMPRESSED
KEY_BLOCK_SIZE=4;
这里创建了一个,压缩后页面大小为4K(默认为8K)的压缩数据表。
(全文完)
Leave a Reply