一直以来实现数据库的零数据丢失都是非常有挑战,尤其是跨可用区的场景下。很多核心系统为了实现这一点都投入了大量的智慧和金钱。Amazon RDS在文档都明确的写到,数据库在多AZ之间的数据是保持同步的(注:同步是指数据写入两边要同时写成功,即使一边不可用,已经提交的事务在另一边一定是成功的)。一直以来,我也很好奇Amazon RDS在哪个层面实现的同步复制。
这个问题原本也是没有太大疑问的,可以推测应该是通过EBS层面的块复制来下。依据有两方面,有一些公开的Amazon RDS一些架构图中可以看到有EBS复制的箭头说明。另外,还有一点,只有通过EBS的复制实现跨可用区数据一致性,才可能在RDS支持的多种数据库,如MySQL、SQL Server、Oracle等,上保持架构上一致。否则,不同数据库类型的高可用和复制架构可能相差很大。
但是,之前很长时间我还是有一个疑问,Amazon RDS复制到底是在数据库逻辑层实现的还是在EBS物理层实现的。
既然有上面的猜测,那为什么产生了这个疑问呢?是因为,在Aurora很多的对外介绍材料(包括论文、架构介绍的slide)中,会放一个MySQL架构来突出Aurora的架构优势。这个图一直让我误以为Amazon RDS使用了数据库的binlog的复制。在了解Aurora的时候大家经常会看到如下架构图作为反面案例(参考):
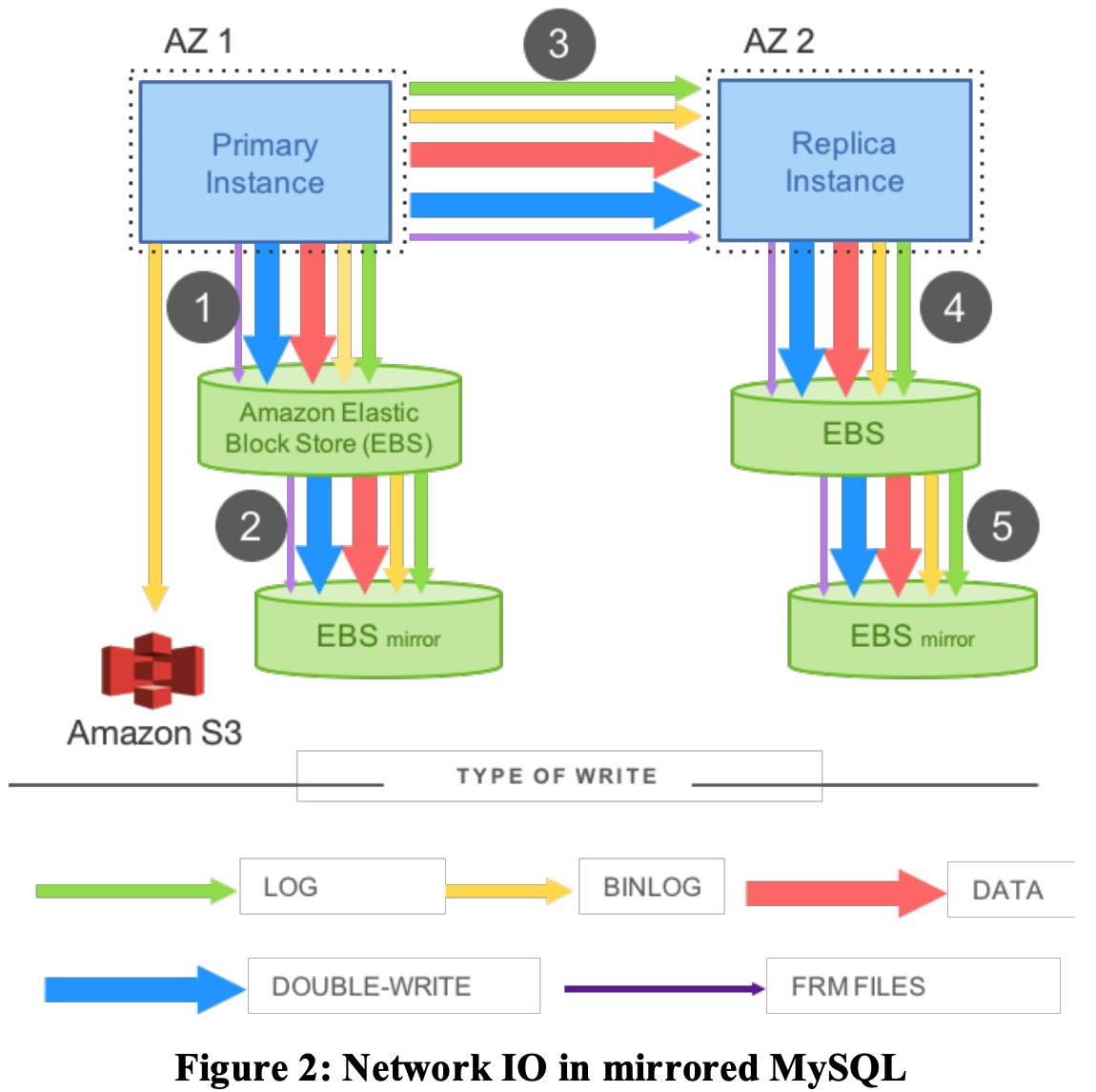
因为这幅图的误导,让我一度以为Amazon RDS MySQL用了这种复制方式。但是仔细一想,应该是不可能的,使用EBS实现多可用区复制是一种更加一致、通用的方案。为了找到这一点的实锤证据,就稍微做了一些搜索。最终,在Youtube上AWS Re:Invent大会上的演讲找到了AWS同学详细关于这个点的阐述,具体的描述如下(参考: AWS re:Invent 2017: Deep Dive on Amazon Relational Database Service (RDS) (DAT302)):
...They're replicating synchronously now that replication is at the block level.It's not a logical replication. It's actually physically replication the storage blocks...
另外,还有明确表示EBS复制关系的胶片如下:
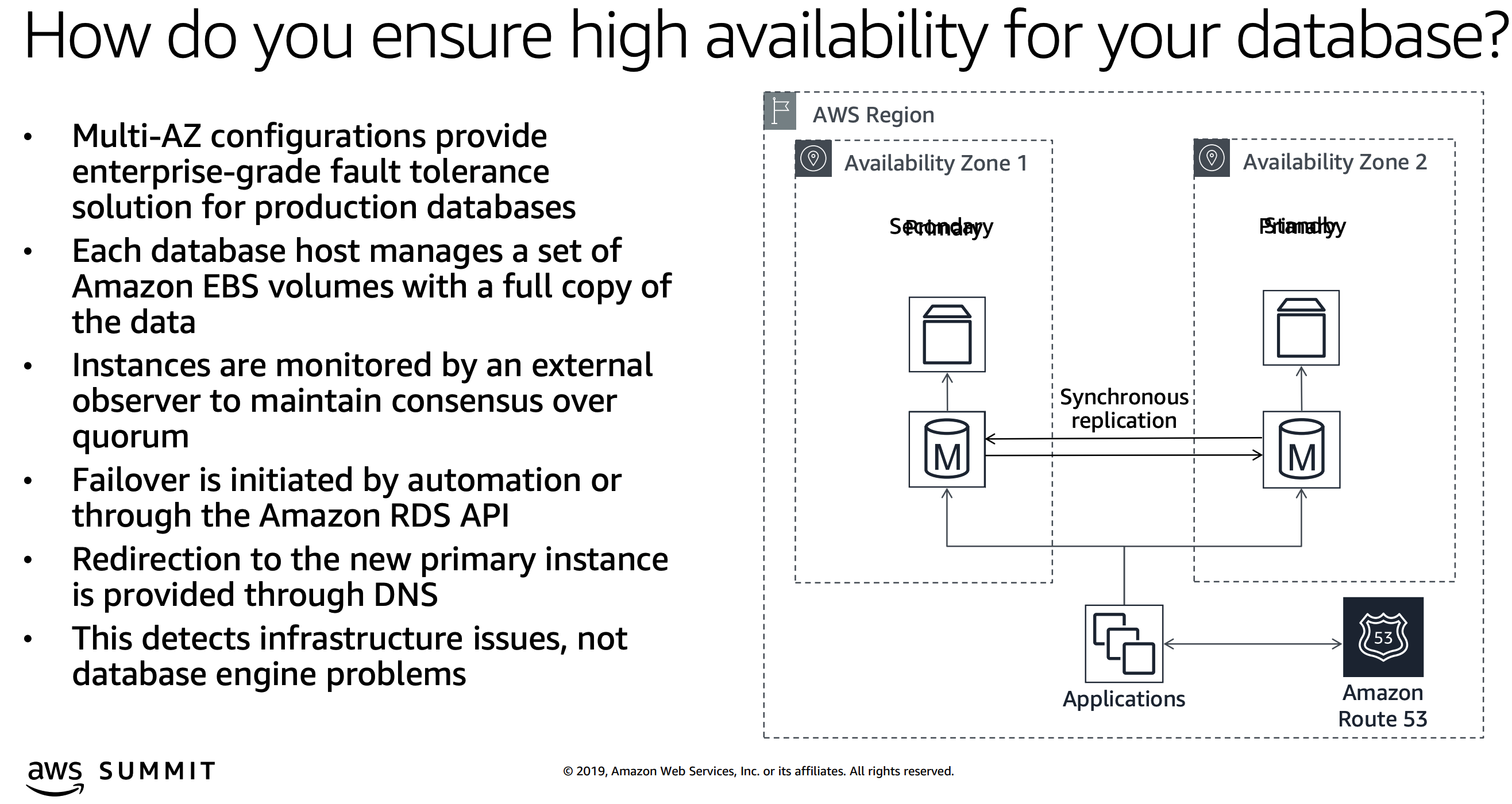
好了,这个问题的疑问就到此为止了,各种证据已经实锤。
那么,Aurora论文中的架构图是怎么回事呢?事实上,当用户在EC2/ECS自建数据库的时候,架构应该就是上面Figure 2。
Leave a Reply