在InnoDB中,buffer pool里面的dirty page一方面可以加快数据处理速度,同时也会造成数据的不一致(RAM vs DISK)。本文介绍了dirty page是如何产生,以及InnoDB如何利用redo log如何消除dirty page产生的数据不一致。
- 当事务(Transaction)需要修改某条记录(row)时,InnoDB需要将该数据所在的page从disk读到buffer pool中,事务提交后,InnoDB修改page中的记录(row)。这时buffer pool中的page就已经和disk中的不一样了,我们称buffer pool中的page为dirty page。Dirty page等待flush到disk上。
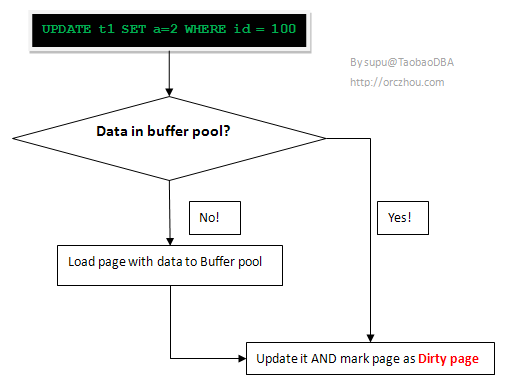
- dirty page既然是在Buffer pool中,那么如果系统突然断电Dirty page中的数据修改是否会丢失?这个担心是很有必要的,例如如果一个用户完成一个操作(数据库完成了一个事务,page已经在buffer pool中修改,但dirty page尚未flush),这时系统断电,buffer pool数据全部消失。那么,这个用户完成的操作(导致的数据库修改)是否会丢失呢?答案是不会(innodb_flush_log_at_trx_commit=1)。这就是redo log要做的事情,在disk上记录更新。
- redo log在每次事务commit的时候,就立刻将事务更改操作记录到redo log。所以即使buffer pool中的dirty page在断电时丢失,InnoDB在启动时,仍然会根据redo log中的记录完成数据恢复。
- redo log的另一个作用是,通过延迟dirty page的flush最小化磁盘的random writes。(redo log会合并一段时间内TRX对某个page的修改)

- 正常情况下,dirty page什么时候flush到disk上?
1).redo log是一个环(ring)结构,当redo空间占满时,将会将部分dirty page flush到disk上,然后释放部分redo log。这种情况可以通过Innodb_log_wait(SHOW GLOBAL STATUS)观察,情况发生该计数器会自增一次。
2).当需要在Buffer pool分配一个page,但是已经满了,并且所有的page都是dirty的(否则可以释放不dirty的page),通常是不会发生的。这时候必须flush dirty pages to disk。这种情况将会记录到Innodb_buffer_pool_wait_free中。一般地,可以可以通过启动参数innodb_max_dirty_pages_pct控制这种情况,当buffer pool中的dirty page到达这个比例的时候,将会强制设定一个checkpoint,并把dirty page flush到disk中。
3).检测到系统空闲的时候,会flush,每次64 pages。 - 涉及的InnoDB配置参数:innodb_flush_log_at_trx_commit、innodb_max_dirty_pages_pct;状态参数:Innodb_log_wait、Innodb_buffer_pool_wait_free。
参考文献
Leave a Reply