上图先。
如果还不了解Semi-sync可以阅读(Manual | 概述)
1. 优点
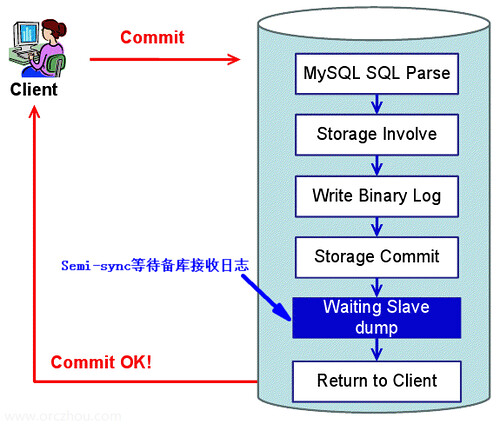
当事务返回客户端成功后,则日志一定在至少两台主机上存在。
MySQL在加载并开启Semi-sync插件后,每一个事务需等待备库接收日志后才返回给客户端。如果做的是小事务,两台主机的延迟又较小,则Semi-sync可以实现在性能很小损失的情况下的零数据丢失。
2. 缺点
完成单条事务增加了额外的等待延迟,延迟的大小取决于网络的好坏。
Semi-sync不是分布式事务,主库会在自己完成事务后,等待备库接收事务日志。
3. 主机Crash时的处理
备库Crash时,主库会在某次等待超时后,关闭Semi-sync的特性,降级为普通的异步复制,这种情况比较简单。
主库Crash后,那么可能存在一些事务已经在主库Commit,但是还没有传给任何备库,我们姑且称这类事务为”墙头事务“。”墙头事务”都是没有返回给客户端的,所以发起事务的客户端并不知道这个事务是否已经完成。
这时,如果客户端不做切换,只是等Crash的主库恢复后,继续在主库进行操作,客户端会发现前面的”墙头事务”都已经完成,可以继续进行后续的业务处理;另一种情况,如果客户端Failover到备库上,客户端会发现前面的“墙头事务”都没有成功,则需要重新做这些事务,然后继续进行后续的业务处理。
4. 其他
可以做多个备库,任何一个备库接收完成日志后,主库就可以返回给客户端了。
网络传输在并发线程较多时,一次可能传输很多日志,事务的平均延迟会降低。
“墙头事务”在墙头上的时候,是可以被读取的,但是这些事务在上面Failover的场景下,是被认为没有完成的。
累了,听首歌,伸个懒腰吧:)
Leave a Reply