更进一步,本文将从零构建一个浅层的前馈神经网络,实现手写数字0和1的识别。示例手写数字如下图所示。整体实现包括数据预处理、参数初始化、forward/backword propagation、训练与预测。





问题描述
使用 Python ,但不使用任何深度学习框架,编写一个浅层的神经网络实现,识别 MNIST 数据集中的手写数字 0 和 1。
目录
前置知识
- 熟悉Python 、NumPy的使用
- 了解神经网络的表示与forward propagation
- 了解 backward propagation
- 了解 MNIST 数据集
数据说明
这里的手写数字使用了数据集 MNIST,该数据集有着机器学习界的“果蝇”之称。里面包含了大量经过预处理的手写数字,这里选择其中标记为0或1的图片进行训练。并使用对应的测试集,验证训练的神经网络的效果。
这里取一张 MNIST 中的图片,以及对应的像素数据,以帮助直观理解其中的数据。MNIST 中的图片数据可以理解为一个如下的 28*28 的数组,其所代表的图片也如下图所示:


更为具体的,数组中的每一个数值代表了图片中的某个像素的灰度值,0代表黑色,255代表白色,这之间的值则代表介于之间的灰色。
MNIST 原始数据可以在:“THE MNIST DATABASE of handwritten digits”页面获取。也可以直接使用 Python 中模块keras.datasets获取。本程序使用后者方式获取。
实现概述
这里的使用了两层神经网络,即一个隐藏层,一个输出层,因为这是二分类问题,所以输出层使用logistic函数,而隐藏层则使用了 ReLU 作为激活函数。隐藏层的神经元是一个动态参数(超参数),在测试时,可以调整为10~300之间不等。输入层则是,MNIST 的图片,也就是一个28*28个数组。
这里使用了最为基础的Gradient Descent算法,有时候也被称为Batch Gradient Descent。
数据预处理
在 Python 中可以使用 keras.datasets模块便捷的获取 MNIST 的数据集。这里编写了一个简单的函数,将该数据集中0和1相关的图片筛选出来,然后将数组的维度,转化为需要的维度。例如,期望的输入数组的维度为\( (n^{[0]},m) \),其中 \( n^{[0]} \) 表示输入的特性(feature)数量,这里也就是 784(即28*28),\( m \)表示样本个数。
具体代码如下:
# return only data lable 0 or 1 from MNIST for the binary classification
def filter_mnist_data(data_X, data_y):
data_filter = np.where((data_y == 0) | (data_y == 1))
filtered_data_X, filtered_data_y = data_X[data_filter], data_y[data_filter]
r_data_X = filtered_data_X.reshape(filtered_data_X.shape[0],filtered_data_X.shape[1]*filtered_data_X.shape[2])
return (r_data_X, filtered_data_y)
(train_all_X, train_all_y), (test_all_X, test_all_y) = mnist.load_data()
(train_X,train_y) = filter_mnist_data(train_all_X, train_all_y)
(test_X ,test_y ) = filter_mnist_data(test_all_X, test_all_y)
X = train_X.T
Y = train_y.reshape(1,train_y.shape[0])超参数的配置
该程序涉及的超参数(hyper-parameter)包括:隐藏层神经元个数 \( n_1 = 10 \)、学习率 \( \alpha = 0.5 \)、迭代次数等。
# hyper-parameter; read the comments above for structure of the NN
n0 = X.shape[0] # number of input features
n1 = 10 # nerons of the hidden layer
n2 = 1 # nerons of the output layer
iteration_count = 500
learning_rate = 0.5feature scaling和参数初始化
为了增加训练的速度,这里对输入进行了“标准化”,将所有的数据,归一化为均值为0、方差为1的数据集。具体的步骤如下:
# feature scaling / Normalization
mean = np.mean(X,axis = 1,keepdims = True)
std = np.std( X,axis = 1,keepdims = True)+0.000000001
X = (X-mean)/std注意:实现过程中需要注意的是,如果对输入进行了标准化,那么在预测时也需要对预测的输入进行相同的归一化。所以这里的均值和方差,需要记录下来,以备后续使用。这里给方差额外加了一个非常小的数字,一般是没有必要的,这里是为了防止输入数据全部都相同,即方差为0。
此外,为了增加训练的速度,也参考业界通用做法,对输入也进行了随机初始化,具体如下:
# initial parameters: W1 W2 b1 b2 size
np.random.seed(561)
W1 = np.random.randn(n1,n0)*0.01
W2 = np.random.randn(n2,n1)*0.01
b1 = np.zeros([n1,1])
b2 = np.zeros([n2,1])Forward Propagation / Backward Propagation
Forward Propagation 总是简单的。Backward Propagation 本身的计算与推导是非常复杂的,这里不打算详述(后续再单独介绍)。这里把 Backward Propagation 的计算结果列举如下。对于输出层:
$$
\begin{align}
dW^{[l]} & = \frac{\partial J}{\partial W^{[l]}} \\
& = \frac{\partial J}{\partial Z^{[l]}} @ (A^{[l-1]})^T
\\
dZ^{[l]} & = \frac{\partial J}{\partial Z^{[l]}} \\
& = \frac{1}{m}(A^{[l]} – Y)
\end{align}
$$
这里的 @ 表示矩阵乘法符号。 上标 T表示矩阵转置。这里一共两层,故这里的 \( l = 2 \) 。
对于隐藏层:
$$
\begin{align*}
dW^{[k-1]} & = \frac{\partial J}{\partial W^{[k-1]}} \\
& = \frac{\partial J}{\partial Z^{[k-1]}} @ (A^{[l-2]})^T &
\\
dZ^{[k-1]} & = \frac{\partial J}{\partial Z^{[k-1]}} \\
& = (W^{[k]})^T @ \partial Z^{[k]} \cdot g\prime(Z^{[k-1]}) &
\end{align*}
$$
因为这里只有一个隐藏层和一个输出层,故这里的 \( k = 2 \);相同的,这里的 @ 表示矩阵乘法符号;这里的 \( \cdot \) 表示对应元素相乘(element-wise);函数 \( g \) 表示 ReLU函数。
具体的代码实现:
# forward propagation
A0 = X
Z1 = W1@X + b1 # W1 (n1,n0) X: (n0,m)
A1 = np.maximum(Z1,0) # relu
Z2 = W2@A1 + b2
A2 = logistic_function(Z2)
dZ2 = (A2-Y)/m
dW2 = dZ2@A1.T
db2 = np.sum(dZ2,axis=1,keepdims = True)
dZ1 = W2.T@dZ2*(np.where(Z1 > 0, 1, 0)) # np.where(Z1 > 0, 1, 0) is derivative of relu function
dW1 = dZ1@A0.T
db1 = np.sum(dZ1,axis=1,keepdims = True)训练迭代
每次训练迭代都需要根据样本数据,进行一次上述的 Forward Propagation / Backward Propagation ,然后更新新的参数值,以用于下一次迭代,具体的实现如下:
cost_last = np.inf # very large data,maybe better , what about np.inf
for i in range(iteration_count):
...
Forward Propagation / Backward Propagation
...
W1 = W1 - learning_rate*dW1
W2 = W2 - learning_rate*dW2
b1 = b1 - learning_rate*db1
b2 = b2 - learning_rate*db2使用测试数据集验证训练效果
在完成训练后,就可以对测试集中的数据进行验证了。需要注意的是,在前面做了“feature scaling”,这里需要对应将输入数据做对应的处理。将预测结果,与标注数据进行对比,就可以确定该模型的效果了。
# Normalization for test dataset
X = (test_X.T - mean)/std
Y = test_y.reshape(1,test_y.shape[0])
Y_predict = (logistic_function(W2@np.maximum((W1@X+b1),0)+b2) > 0.5).astype(int)
for index in (np.where(Y != Y_predict)[1]):
print(f"failed to recognize: {index}")
# np.set_printoptions(threshold=np.inf)
# np.set_printoptions(linewidth=np.inf)
# print(test_X[index].reshape(28,28))
print("total test set:" + str(Y.shape[1]) + ",and err rate:"+str((np.sum(np.square(Y-Y_predict)))/Y.shape[1]))完整的代码
完整的代码可以参考 GitHub 仓库中的 ssnn_bear.py 脚本:参考。这里张贴当前版本如下:
"""
super simple neural networks (bear version)
* input x is matrix 784x1 (where 784 = 28*28 which is MNIST image data)
* 30 neurons for the only hidden layer, as n^{[1]} = 30
* output layer: one neuron for classification(logistic)
* using relu for activation function in hidden layer
input layer:
x: (shape 784x1)
X: m samples where m = 12665 , X: 784 x 12665
as : a^{[0]}: 784 x 12665 n^{[0]} = 784
hidden layer:
n^{[1]}: 30
W^{[1]}: (30,784) as (n^{[1]},n^{[0]})
Z^{[1]}: (30,12665) as (n^{[1]},m)
A^{[1]}: (30,12665) as (n^{[1]},m)
output layer:
n^{[2]}: 1
W^{[2]}: (1,30) as (n^{[2]},n^{[1]})
Z^{[2]}: (1,12665) as (n^{[2]},m)
A^{[2]}: (1,12665) as (n^{[2]},m)
output:
y \in [0,1] or p \in {0,1}
Y: (1 x m) ndarray
structure for only one sample:
x_1 -> W*X + B -> relu ->
x_2 -> W*X + B -> relu -> \
... -> ... -> .. -> -> w*x+b -> logistic
x_784 -> W*X + B -> relu -> /
------ -------------------- ------------------
| | |
V V V
input 30 neurons one neuron
feature relu activation output layer
By numpy with m samples:
np.logistic(W2@g(W1@X+b1)+b2) as \hat{Y}: (1 x m) ndarray
dimension analysis:
W2 : (n2,n1)
g(W1@X+b1): (n1,m)
W1 : (n1,n0)
X : (n0,m)
b1 : (n1,1) with broadcasting to (n1,m)
b2: (n2,1) with broadcasting to (n2,m)
grad and notaion:
forward propagation : A1 A2 Z1 Z2
backward propagation: dW1 dW2 db1 db2
more details:
Z1 = W1@X + b1
Z2 = W2@A1 + b2
A1 = g(Z1) -- g for relu
A2 = \sigma(Z2) -- sigma for logistic
dW2 = ((1/m)*(A2-Y))@A1.T
dW2 = dZ2@A1.T where dZ2 = (1/m)*(A2-Y)
A2.shape:(1,m) Y.shape:(1,m) A1.T.shape:(n1,m)
so: dW2.shape: (1,n1)
dW1 = (W2.T@((1/m)*(A2-Y))*g_prime(Z1))@A0.T
dW1 = dZ1@A1.T
where
dZ1 = W2.T@dZ2 * g_prime(Z1)
g_prime is derivative of relu
dW2.shape: (n1,n0)
note: @ for matrix multiply; * for dot product/element-wise
Challenges
1. Understanding the MNIST dataset and labels
2. Understanding gradient caculate and the gradient descent
3. Understanding logistic regression loss function and the caculation
3. Knowing feature normalization
about it:
it's a simple project for human learning how machine learning
version ant : scalar input/one neuron/one layer/binary classification
version bear: vector input/30+1 neurons /two layer/binary classification
by orczhou.com
"""
from keras.datasets import mnist
import numpy as np
# return only data lable 0 or 1 from MNIST for the binary classification
def filter_mnist_data(data_X, data_y):
data_filter = np.where((data_y == 0) | (data_y == 1))
filtered_data_X, filtered_data_y = data_X[data_filter], data_y[data_filter]
r_data_X = filtered_data_X.reshape(filtered_data_X.shape[0],filtered_data_X.shape[1]*filtered_data_X.shape[2])
return (r_data_X, filtered_data_y)
(train_all_X, train_all_y), (test_all_X, test_all_y) = mnist.load_data()
(train_X,train_y) = filter_mnist_data(train_all_X, train_all_y)
(test_X ,test_y ) = filter_mnist_data(test_all_X, test_all_y)
X = train_X.T
Y = train_y.reshape(1,train_y.shape[0])
m = X.shape[1] # number of samples
# hyper-parameter; read the comments above for structure of the NN
n0 = X.shape[0] # number of input features
n1 = 10 # nerons of the hidden layer
n2 = 1 # nerons of the output layer
iteration_count = 500
learning_rate = 0.5
# feature scaling / Normalization
mean = np.mean(X,axis = 1,keepdims = True)
std = np.std( X,axis = 1,keepdims = True)+0.000000001
X = (X-mean)/std
# initial parameters: W1 W2 b1 b2 size
np.random.seed(561)
W1 = np.random.randn(n1,n0)*0.01
W2 = np.random.randn(n2,n1)*0.01
b1 = np.zeros([n1,1])
b2 = np.zeros([n2,1])
# logistic function
def logistic_function(x):
return 1/(1+np.exp(-x))
about_the_train = '''\
try to train the model with:
learning rate: {:f}
iteration : {:d}
neurons in hidden layer: {:d}
\
'''
print(about_the_train.format(learning_rate,iteration_count,n1))
# forward/backward propagation (read the comment above:"grad and notaion")
cost_last = np.inf # very large data,maybe better , what about np.inf
for i in range(iteration_count):
# forward propagation
A0 = X
Z1 = W1@X + b1 # W1 (n1,n0) X: (n0,m)
A1 = np.maximum(Z1,0) # relu
Z2 = W2@A1 + b2
A2 = logistic_function(Z2)
dZ2 = (A2-Y)/m
dW2 = dZ2@A1.T
db2 = np.sum(dZ2,axis=1,keepdims = True)
dZ1 = W2.T@dZ2*(np.where(Z1 > 0, 1, 0)) # np.where(Z1 > 0, 1, 0) is derivative of relu function
dW1 = dZ1@A0.T
db1 = np.sum(dZ1,axis=1,keepdims = True)
cost_current = np.sum(-(Y*(np.log(A2))) - ((1-Y)*(np.log(1-A2))))/m
if (i+1)%(iteration_count/20) == 0:
print("iteration: {:5d},cost_current:{:f},cost_last:{:f},cost reduce:{:f}".format( i+1,cost_current,cost_last,cost_last-cost_current))
cost_last = cost_current
W1 = W1 - learning_rate*dW1
W2 = W2 - learning_rate*dW2
b1 = b1 - learning_rate*db1
b2 = b2 - learning_rate*db2
print("Label:")
print(np.round( Y[0][:20]+0.,0))
print("Predict:")
print(np.round(A2[0][:20],0))
# Normalization for test dataset
X = (test_X.T - mean)/std
Y = test_y.reshape(1,test_y.shape[0])
Y_predict = (logistic_function(W2@np.maximum((W1@X+b1),0)+b2) > 0.5).astype(int)
for index in (np.where(Y != Y_predict)[1]):
print(f"failed to recognize: {index}")
# np.set_printoptions(threshold=np.inf)
# np.set_printoptions(linewidth=np.inf)
# print(test_X[index].reshape(28,28))
print("total test set:" + str(Y.shape[1]) + ",and err rate:"+str((np.sum(np.square(Y-Y_predict)))/Y.shape[1]))简单统计,代码总计180行,其中注释约90行。
运行结果说明
运行该程序会有如下输出:
try to train the model with:
learning rate: 0.500000
iteration : 500
neurons in hidden layer: 10
iteration: 25,cost_current:0.009138,cost_last:0.009497,cost reduce:0.000358
...
iteration: 500,cost_current:0.000849,cost_last:0.000850,cost reduce:0.000001
failed to recognize: 1749
failed to recognize: 2031
total test set:2115,and err rate:0.0009456264775413711在本次训练后,对于测试集中的 2115 中图片,识别的错误率为 0.094%,即有两张图片未能够正确识别。这两张图片的编号分别是1749和2031,对应的图像如下:

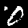
最后
该神经网络在训练后,对于2115张测试集中的图片,仅有2张识别失败。通过该程序,可以看到,神经网络的强大与神奇。
因为神经网络的 Backward Propagation 的推导非常复杂,本文中直接给出了相关公式,后续将独立介绍该部分内容。如果有任何问题可以留言讨论或公众号后台给作者留言。
补充记录
在这个该程序实现中,还遇到了一些其他的问题,记录如下。
一些报错
“RuntimeWarning: overflow encountered in exp: return 1/(1+np.exp(-x))”
当训练或者预测计算过程中,如果出现部分-x值比较大,那么就会出现np.exp(-x)溢出的问题。不过,还好该问题在该场景下并不会影响计算结果,因为这种情况下,1/(1+np.exp(-x))依旧会返回0,而这也是预期中的。
难以分析
在这个识别程序中,最后发现有部分图片是难以识别的,而且无论如何调整参数,部分图片还是难以识别。最好的处理方法当然是增加训练数据集,但现实中可能并不总是能够做到。
而关于模型应该如何优化,这似乎是难以分析,无从入手。
Leave a Reply