0. 为什么写这篇博客
Linux的top或者ps都可以查看进程的cpu利用率,那为什么还需要了解这个细节呢。编写这篇文章呢有如下三个原因:
* 希望在脚本中,能够以过”非阻塞”的方式获取进程cpu利用率 * ps无法获得进程当前时刻的CPU利用率;top则需要至少1秒才能获得进程当前的利用率 * * 好奇
Linux的top或者ps都可以查看进程的cpu利用率,那为什么还需要了解这个细节呢。编写这篇文章呢有如下三个原因:
* 希望在脚本中,能够以过”非阻塞”的方式获取进程cpu利用率 * ps无法获得进程当前时刻的CPU利用率;top则需要至少1秒才能获得进程当前的利用率 * * 好奇
概述:本文讨论主机在发送一个TCP数据包后,如果迟迟没有收到ACK,主机多久后会重传这个数据包。主机从发出数据包到第一次TCP重传开始,RFC中这段时间间隔称为retransmission timeout,缩写做RTO。本文会先看看RFC中如何定义RTO,然后看看Linux中如何实现。本文旨在分享:当遇到了TCP层问题改如何去查找、阅读文档,该如何去在Linux源码中寻求答案。
在分析MySQL Semi-sync故障时,我们用Tcpdump+Wireshark(感谢淘宝雕梁)抓住当时的网络包传送细节,观察到了一次TCP重传最终导致了Semi-sync超时:
第一次传输
13:55:11.893291 master => slave Binlog pos:319890197
重传:
13:55:12.094596 master => slave Binlog pos:319890197看到两次传送间隔约201毫秒,即第一次传输201毫秒后,还没有收到ACK响应,TCP认为传输超时,开始重传。
疑问:host和host之间的RTT大约是0.5毫秒,为什么第一次重传需要等200毫秒?(我希望是<20ms)socket程序可以配置吗RTO吗?TCP有参数可配置RTO吗?
翻开TCP/IP详解找到关于TCP Retransmission章节,较详细的介绍TCP的超时机制,书中是个概述,于是又找到RFC1122。
RFC1122的4.2.2.15和4.2.3.1都介绍了Retransmission Timeout的处理(说来惭愧,这是第一次阅读TCP相关RFC)。
在RFC中搜索Retransmission发现RFC 793 1122 2988 6298都有对重传算法、和初次重传超时的描述。于是开始阅读这个四个RFC,耗时约2小时,了解了大致的重传超时算法。
(more…)每次深入了解一个技术问题,随着挖据的深入,都发现其背后总非常深的背景知识,甚至需要深入到很多底层系统,这个过程有时会让自己迷失,会让自己忘了当初的目的。
在前篇中介绍系统启动时内存的使用情况,本篇将介绍简要Linux如何接管主机的物理内存、组织内存,最后会较为详细的介绍Linux分配内存的一段代码。
前面说了,Linux MM系统细节非常多,自己在探究的时候,也是尝试尽量抓住主线,这里也只能抽取了一些“主线剧情”介绍,其中还可以扩展出很多细节,看客感兴趣可以自己深究,后续如果兴趣还在,我也还会继续写出来。内核版本如果没有特别说明,就是使用2.6.33版本。
先声明一下,这里说的Linux都是运行Intel X86架构的。从80386开始,为了更好支持内存管理、虚拟内存技术,x86架构开始支持处理器的分页模式(分页是基于分段)。系统将内存分为一个个固定大小的块,称作“page frames”,x86架构每一个“page frames”大小为4096字节。Linux中使用struct page结构来描述一个“page frames”【链接中给出了2.6.18内核下的Page结构】,一个Page结构对应了一个物理内存页。
在Linux中,所有的struct page对象都放在一个数组mem_map,mem_map每一个元素对应一个Page。

在NUMA架构下,系统根据CPU的物理颗数,将内存分成对应的Node。例如,两颗物理CPU,16GB内存的硬件:系统则将内存分成两个8GB,分别分配给两颗CPU:
每一个Node,系统又将其分为多个Zone,64位x86架构下(参考:8.1.5),分为两个ZONE_DMA(低16MB,)、ZONE_NORMAL(其余内存)。所以NUMA架构下的内存分配,也就是在各个zone分配内存。
从底层系统的角度,内存分配有如下函数(这里介绍的底层函数,和上层函数的关系,以后再介绍):

这里来调查一下函数alloc_pages都做了些什么,都调用了哪些函数:

free_area是一个底层保存空闲内存页的数组,有着特殊的结构,它也是内存分配Buddy system的核心变量。
上面函数get_page_from_freelist【mm/page_alloc.c】通过遍历系统中各个zone,来寻找可用内存,根据Linux系统中zone_reclaim_mode的设置不同,遍历时的行为略有不同。zone_reclaim_mode是Linux中的一个可配置参数,为了解该参数如何影响内存分配,那就打开get_page_from_freelist的代码,仔细看看遍历各个zone的流程:

上面看到,zone_reclaim_mode非零时,如果某个zone内存不够,则会尝试出发一次内存回收工作(zone_reclaim),等于零时,则直接尝试写一个zone。
上面是2.6.33内核的代码流程图,2.6.18(RHEL5.4的内核)中则因为没有zcl相对简单一些:

流程图中可以看到,zone_reclaim_mode非零时,get_page_from_freelist【mm/page_alloc.c】函数中会调用zone_watermark_ok扫描free_area,如果当面有没有足够的可用内存,就会调用zone_reclaim【mm/vmscan.c】函数回收内存,zone_reclaim实际调用zone_reclaim【mm/vmscan.】收回内存。
每次深入了解一个技术问题,随着挖据的深入,都发现其背后总非常深的背景知识,甚至需要深入到很多底层系统,这个过程有时会让自己迷失,会让自己忘了当初的目的。如果是Linux方面的技术问题,一般最后会收缩到“体系结构”、“Linux原理”和“算法”,这恰恰对应了计算机系考研时候的三门课程:体系结构、操作系统、和数据结构
参考:
Understanding the Linux Kernel, 3rd Edition
广告时间:工作机会–MySQL Hacker
随着要维护的服务器增多,遇到的各种稀奇古怪的问题也会增多,要想彻底解决这些“小”问题往往需要更深的Linux方面的知识。越专业、分工越细的工程师,在这方面的要求也就越高。这次,对MySQL Swap的问题的探索过程,就一不小心掉进了Linux Memory Managemant(Linux MM)的研究中去了,爬了很久才出来,这里做一个系列笔记。
笔记中很多内容都是参考《Understanding the Linux Kernel, 3rd Edition》、Linux Source Code等地方,自己再做了一些总结,觉得有意义的总结这里记录一下,供参考。
Linux MM是一个比较猥琐的体系,虽然理论不太多,但是细节非常多。要从底层物理内存管理到上层虚拟内存管理整个关节打通,一方面需要较多底层架构知识、还需要很深的Linux知识。既然是学习笔记,先说一下我的学习资料:
1. Linux Memory Management David A Rusling 这本书很老了,当时的Kernel还是2.0.33版本的;这本书的优点在于抽象得很到位,把Linux_MM的基本模块、思想都通俗易懂的介绍了一遍。这也是kernel-docs.txt中推荐的读物之一;
2. 《Understanding the Linux Kernel, 3rd Edition》中的第二、八、十七章 这是基于2.6内核,非常有参考价值,介绍得非常细致,可以结合内核的源代码一起来看。
3. Linux Source Code 只看了几个自己关心的函数,没那么难:)
我不是计算机科班出身,体系结构的基础比较差,所以刚开始入门的时间相对较长,前后大概历时一个月,实际伏案时间约50小时,而这也只是一个开始

上面是一幅简图,后面会分别介绍,Kernel如何使用内存、Kernel如何管理分配内存、用户空间的内存管理。对于其中的一些细节则会单独介绍,例如大页内存,内存回收算等等。
开机的第一个过程是BIOS自检,BIOS使用0x00000000到0x10000(1MB)内存,这1MB内存包括了自检程序、自检结果、还留一部分给显示设备使用;自检完成后,开始载入Linux内核,Linux从1MB开始使用物理内存,一般5MB就足够了,在内核的符号信息中可以看到,Linux内核从_text开始,_edata处结束
简图:

这里不涉及x86架构下的分页、分段细节,后面会单独介绍之。
这一篇很简单,是一个开始:)
【update 2011-03-29】
在64位系统中,Linux(2.6.18)从2MB开始使用物理内存。(32位系统,仍然是从1MB开始)
参考文献:
[1]. http://cateee.net/lkddb/web-lkddb/PHYSICAL_START.html
广告时间:工作机会–MySQL Hacker
也忘了第一次用Top观察Linux运行状态是什么时候了,不过最近吧Top的文档收获不少。
z :打开/关闭彩色显示 x :高亮显示排序列
在使用top命令后,“先按z键,再按x键”,这时屏幕会彩色显示输出,白色显示的列是当前排序的列;偶尔还会有一些白色显示行,这些行是当前正在运行进程。使用该参数可以帮助我们更清楚的看到排序列。例如,我想按照cpu使用排序来查看进程:
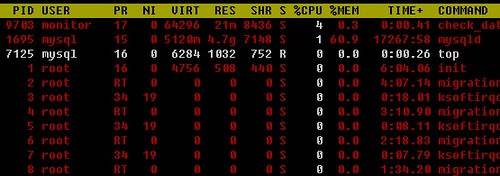
使用了top-z-x命令后是不是看得清晰了一些:)
1 :SMP的系统,会单独显示各个CPU的运行状态
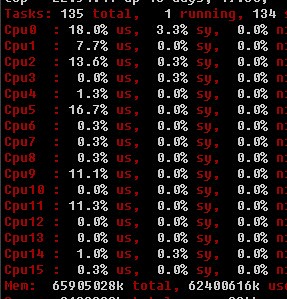
< :改变排序列 > :改变排序列
top-z-x-< 试试就知道是什么意思了:) 。例如,默认是按照cpu使用率排序的,现在我想看看安装使用的虚拟内存排序看看,使用命令top-z-x-<-<-<-<-< :
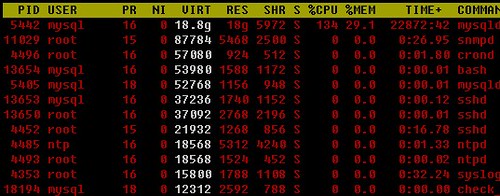
W :把当前配置文件到home目录下.toprc配置文件中 F or O :支持更强的选择排序列的方式 -b :参数可以帮你在脚本中使用top命令 -n :配合-b使用,表示重新刷新一定次数后退出 -d :刷新延时时间。例如-d 5 表示top每隔5秒刷新一次。(默认是3秒)
就这些吧,更多请查看top-h或者RTFM。
最后,各位看官,工作之余别忘了多多运动,没什么比健康更重要了:)
前面写了两篇文章,分别介绍了Flashcache的基本原理和编译安装,本文介绍一下Flashcache的配置。
假设现在你已经编译好了Flashcache,已经装好了ssd盘(假设是/dev/sdb)和sas盘(假设需要使用的是分区/dev/sda12,这可能是一个RAID组)。接下来,看看如何使用Flashcache将上面两个设备虚拟成一个带缓存的块设备。
注:请备份你的数据先!!!特别是/dev/sdb,这个设备上的数据将会被清空;理论上/dev/sda12上的数据不会有任何丢失。
首先确保sda12没有被挂载,如果挂载了,使用umount卸载之,然后使用flashcache_create创建设备:
如果是sudo帐号可能会遇到如下的报错: (more…)