当需要在机器之间传输400GB文件的时候,你就会非常在意传输的速度了。默认情况下(约125MB带宽,网络延迟17ms,Intel E5-2430,本文后续讨论默认是指该环境),scp的速度约为40MB,传输400GB则需要170分钟,约3小时,如果可以加速,则可以大大节约工程师的时间,让攻城师们有更多时间去看个电影,陪陪家人。
1. 结论:使用如下命令可以让scp速度提升50~150%
scp -r -c arcfour128 ...
scp -r -c aes192-cbc ...
scp -r -c arcfour128 -o "MACs umac-64@openssh.com" ...原因概述:
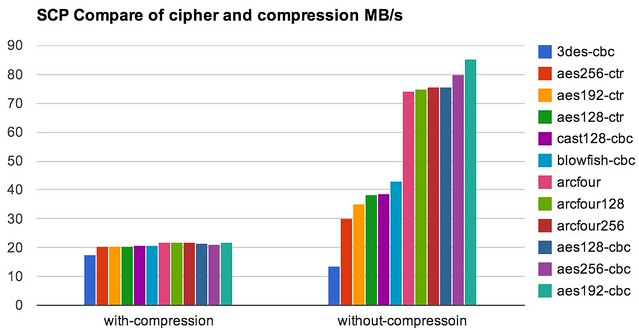
- 通常,更弱的加密算法,scp传输速度更快。这里的测试看到加密算法
-c arcfour128或-c aes192-cbc可以大大加速scp传输 - 用于完整性校验的MAC( message authentication code)算法,对性能约有10%-20%的影响。这里的测试看到
-o "MACs umac-64@openssh.com"是不错的选择。 - 这里测试看到,scp内置的传输压缩并没有什么效果。事实上,合理的使用压缩工具是可以进一步降低传输时间的,具体的参考:使用tar+lz4/pigz+ssh更快的数据传输。你可以通过参数
-o "Compression yes"来启用压缩来观察实际案例中的情况。
声明:测试与数据本身特性有很大关系,本文使用InnoDB的redo log作为测试数据。
2. 测试数据:加密算法和压缩的影响
这里对比了12种ssh中实现的加密算法和是否使用压缩的传输效率,测试文件使用的是InnoDB的1GB*4的日志文件(注意:不同类型的文件测试结果会很不同),这里纵坐标单位为MB/s,数据分为压缩传输和不压缩传输两组:
原始数据:scp_speed.txt
(more…)