简单生活
-
对话式的大语言模型产品已经在改变我的很多日常习惯。鉴于 ChatGTP 国内访问非常不方便,现在也逐渐的在尝试使用通义千问、文心一言等产品。总体上感觉,通义千问和文心一言也都非常不错了,满足基本的日常使用是完全没有问题的,但相比于 ChatGPT 还是差了那么一点意思。这里记录一些日常使用的对比,看看,所谓的那么“一点意思”到底是什么。
简要的问题和简要的回答
这里的问题是:“方括号 英语”。来看看 ChatGPT、通义千问、文心一言的回答:
ChatGPT
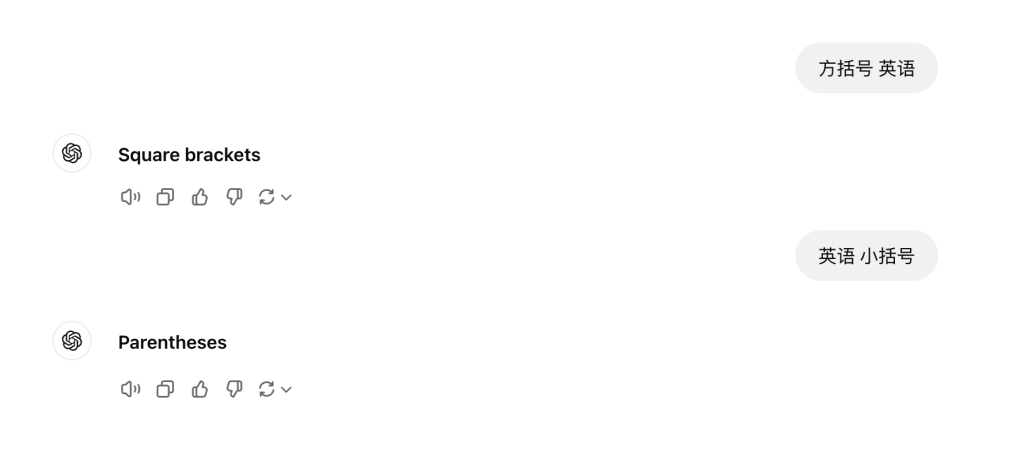
通义千问

文心一言
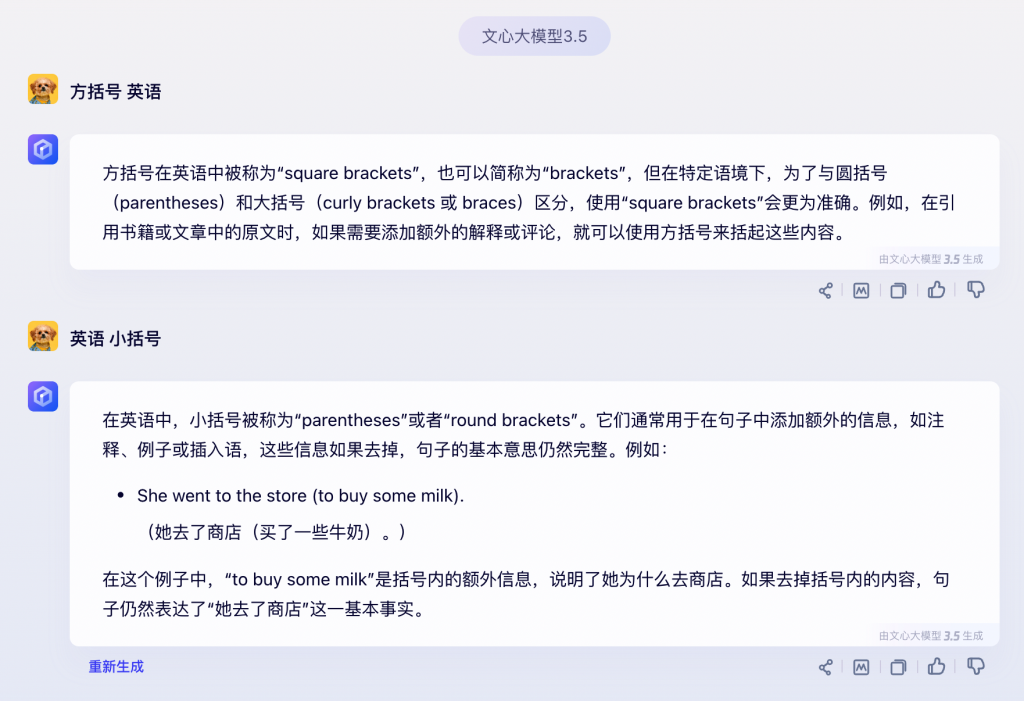
可以看到,三个引擎都给出准确的答案。其中,ChatGPT 给出的回答最为简洁,也是这里我最为偏好的回答。
为什么这里给出简单的回答更好呢?
这里的问题非常简单,这时候,通常也是期望更为简单的回答的。试想这样的场景,你在写一篇英语小短文,但你不确定“方括号”的英语怎么说,恰好你旁边有一个英语很好的同事,你问她:“方括号的英语是?”。如果她像上述通义千问、文心一样,说了一大堆,你可能会打断她,因为当下写材料才是重点,不是想学英语。如果,我真的想学英语的话,我的问题,则可能是这样:“方括号 英语 并给出示例”。
一般的,简单的问题简单回答就可以了。如果用户期待更多信息或者更详尽的回复,通常也会更详细的描述问题。
再比如:“Latex表示一个矩阵(方括号): 变量用x表示,共n_x行,m列。其中行号用下标表示,列用带有括号的上标表示”
ChatGPT

通义千问
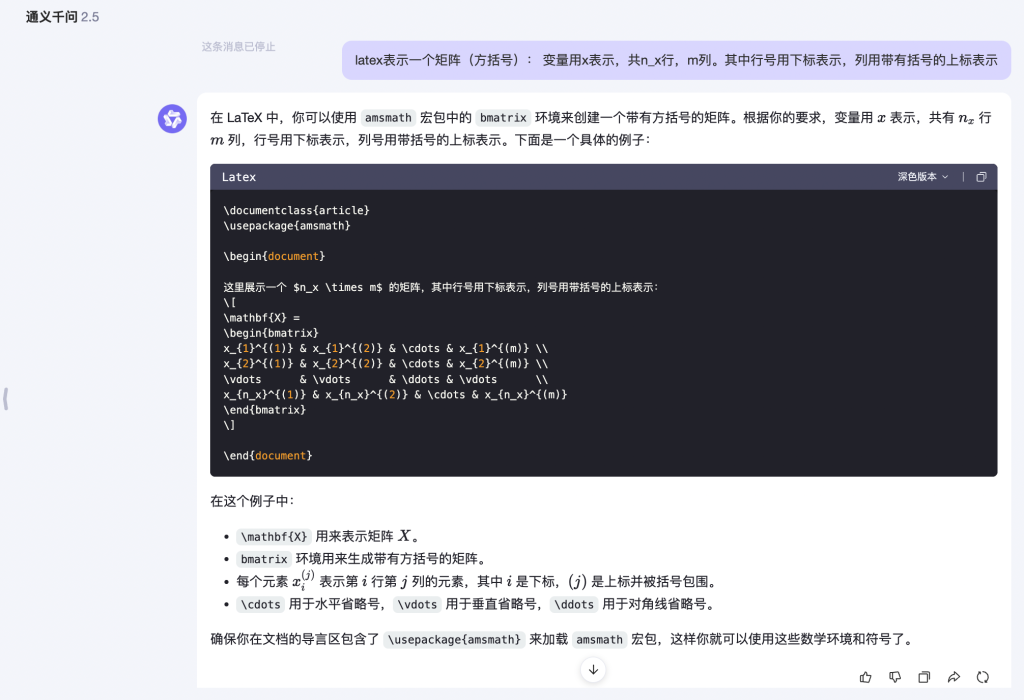
文心一言
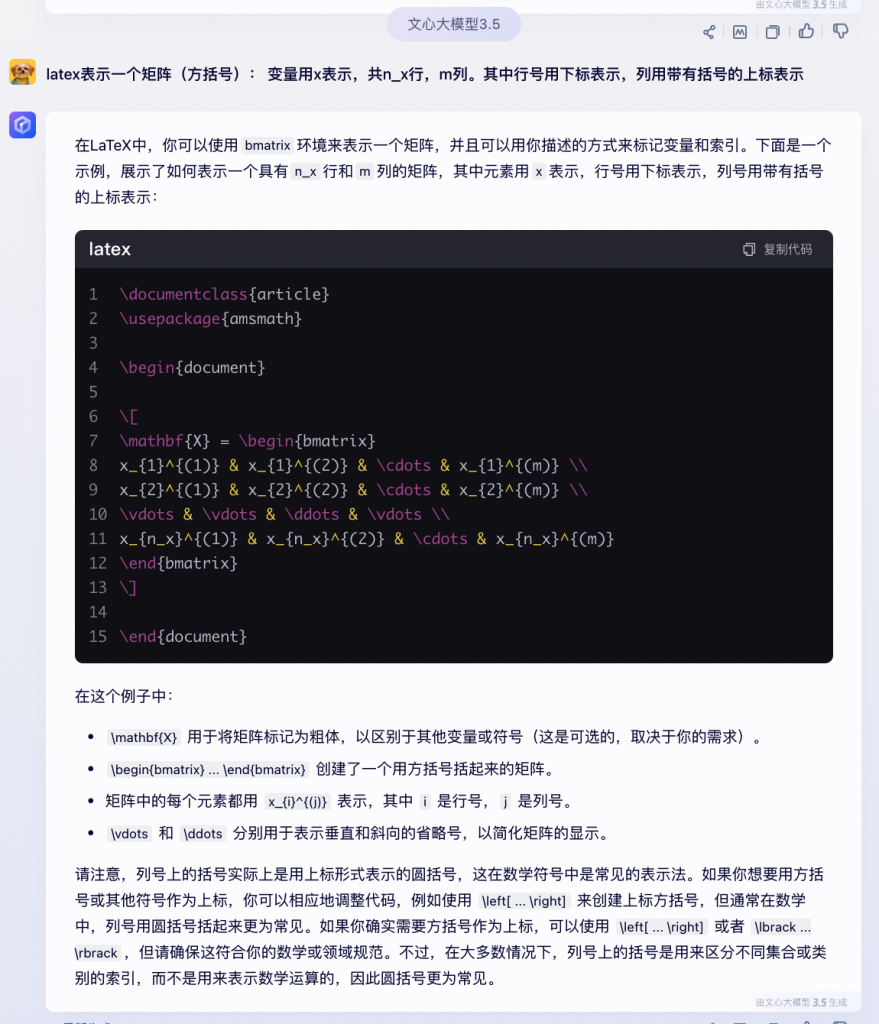
同样的,ChatGPT 更简洁,通义千问次之,文心一言则略显啰嗦。毕竟,这时候我只是想要答案,不想知道获得这个结果的完整的推理过程。
类似的,再比如:
ChatGPT
通义千问
文心一言
“分总/总分总”与“递进式”的结构
我们来看看如下问题,不同的大模型的回答:使用中文介绍一下“Goldsmiths Research Online”
ChatGPT

通义千问

文心一言
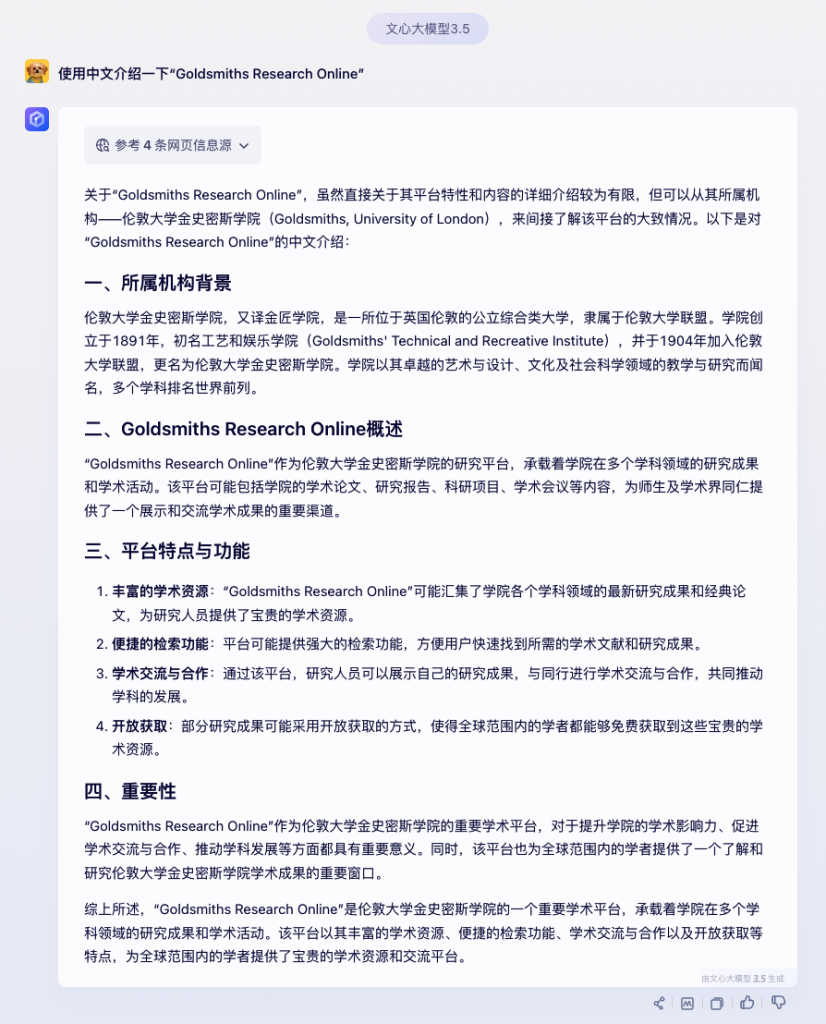
可以看一下这个三个回答的对比,通义千问和文心一言,都使用了“总分总”或“分总”的结构去回答问题。而,ChatGPT则使用了递进式的结构,显得更加自然。
同时,因为通义千问和文心一言总是倾向于使用“总分总”或“分总”类似的结构,所以就就会给人比较呆板一些的感受。
前端展示效果
因为最近在学习机器学习的一些原理,所以,有时候会让 ChatGPT 帮助编写一些数学公式。这里的问题是:x是一个3×4的矩阵,每个元素分别是1…12,使用latex写出这个矩阵。
ChatGPT

通义千问
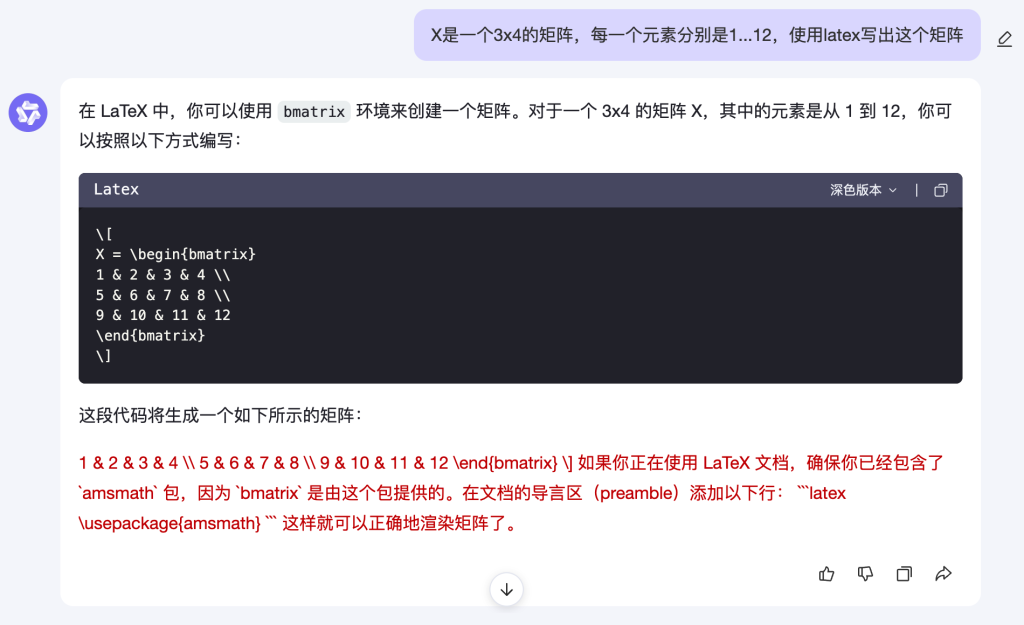
文心一言
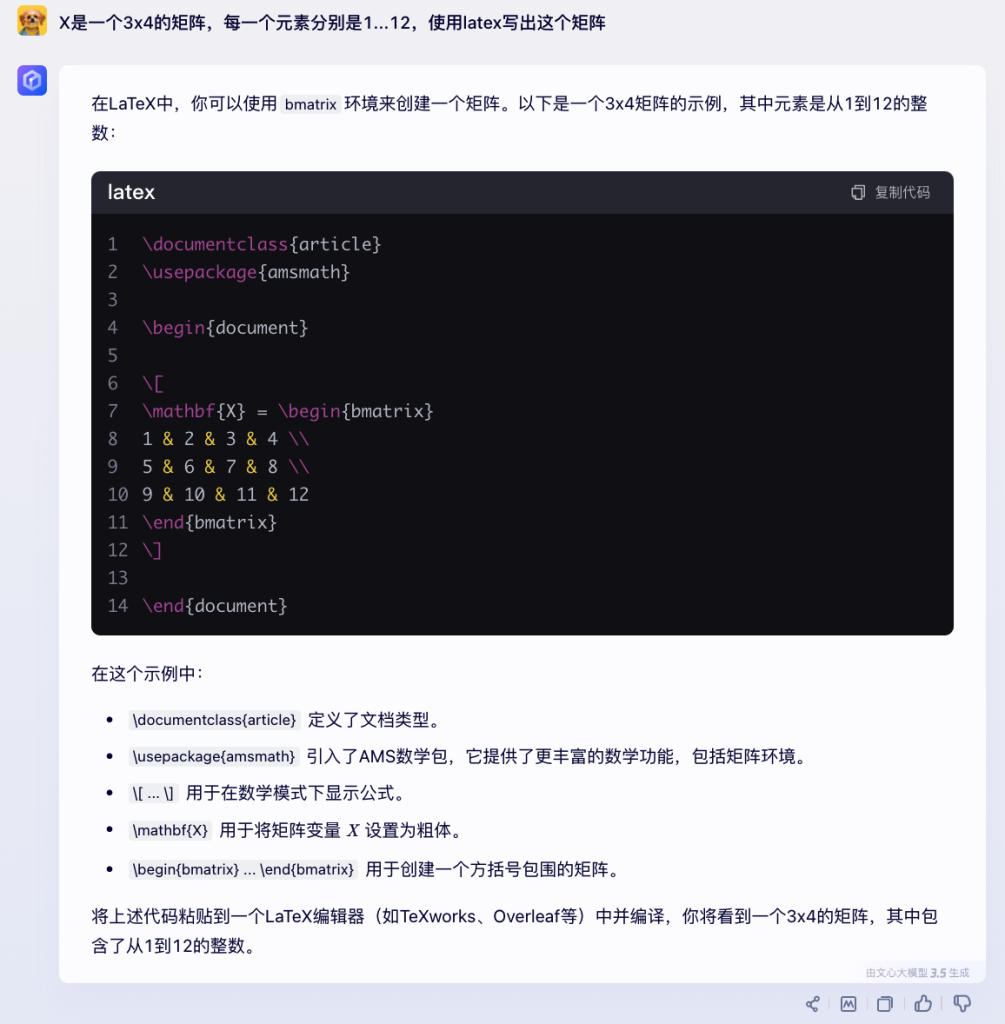
可以看到,ChatGPT 在前端应该使用了类似
Latex的前端组件,有更好的展示效果。而通义千问、文心一言则没有使用类似组件去展示。根据测试,通义千问、文心一言也都是支持 Latex 的前端展示,只是不会经常使用。最后
总体感觉,在日常使用中,通义千问、文心一言和 ChatGPT 差别并不是很明显,早期通过各种方式去科学访问 ChatGPT 现在看起来必要性并没有那么高了。但,在一些细节点上,还存在一些差距,期待通义千问、文心一言都后续的版本能够变得更强。
-
Oracle Cloud 是所有云平台最先支持 9.0 版本的。这里,我们来看看该版本的“标准性能”表现如何。
测试实例与环境说明
这里使用的实例类型是:
MySQL.4,单个节点为4 ecpu 32gb,测试区域选择的是“东京”(ap-tokyo-1),多可用区(FAULT DOMAIN)的版本,测试实例存储空间大小为 100 gb。即:instance_type=MySQL.4 vcpu_per_node=4 memory_size_per_node=32 region=tokyo availability=multi-az storage_size=100 db_version=8.0.39/8.4.2/9.0.1性能对比
本次测试分别测试了 8.0.39/8.4.2/9.0.1 这三个版本。详细的性能对比如下:
data MySQL80 MySQL84 MySQL90 4 3551 3606 3360 8 5936 5378 5256 16 8054 8186 7287 32 8317 8029 7817 48 8130 8204 7911 64 7838 7981 8060 96 8504 8430 8172 128 8198 8286 8000 192 8043 8053 8112 256 7907 8034 7536 384 8209 8055 8151 512 8386 8030 7872 性能概述
从该“标准”测试来看,9.0.1的性能较为稳定。从上述数据中来看,似乎略微低于 8.0和8.4 版本,但经过调查,主要原因是由于云平台 CPU 资源多少所导致的,而并不是数据库本身的问题。
此外,在今年5月份观察到的8.4性能退化问题(参考),目前也已经解决。
-
再登黄山
·
在去年的5月份和家人一起登过黄山,是个阴雨天,虽“三上三下”看到了“猴子观海”但更多景观多是雾里看花。这次运气非常好,山顶天气晴朗,群山云海、奇松奇石尽收眼底。和很多事情一样,虽黄山上的天气是多变的,但多做几次,老天总能偶尔眷顾。
路线
如下蓝色路线是,当天的行进路线概览:
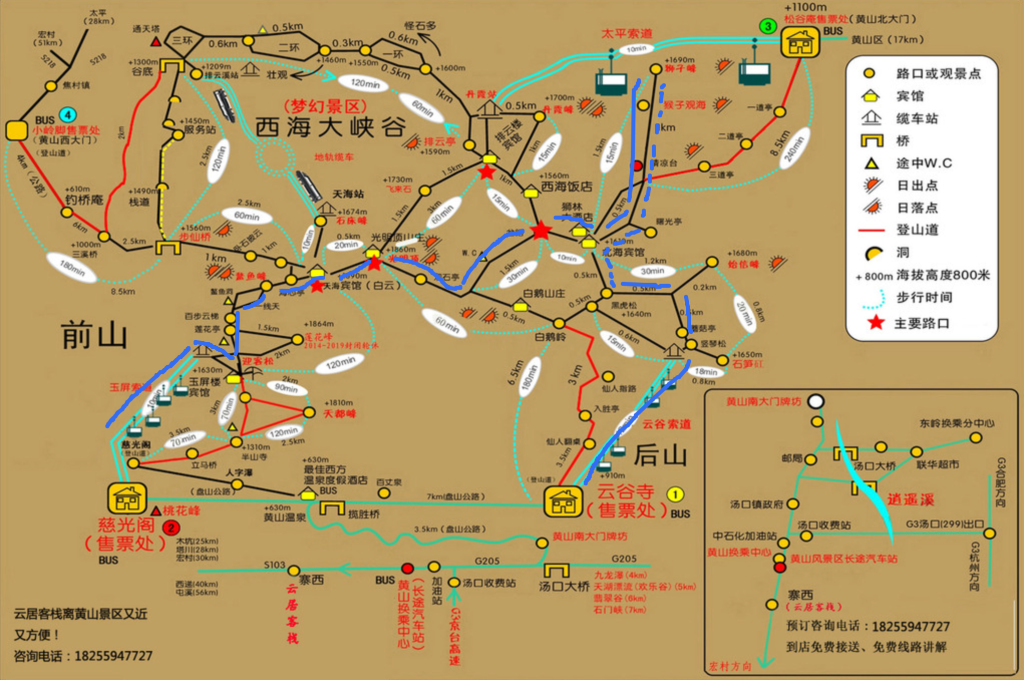
如下路线是GPS记录的详细路线:
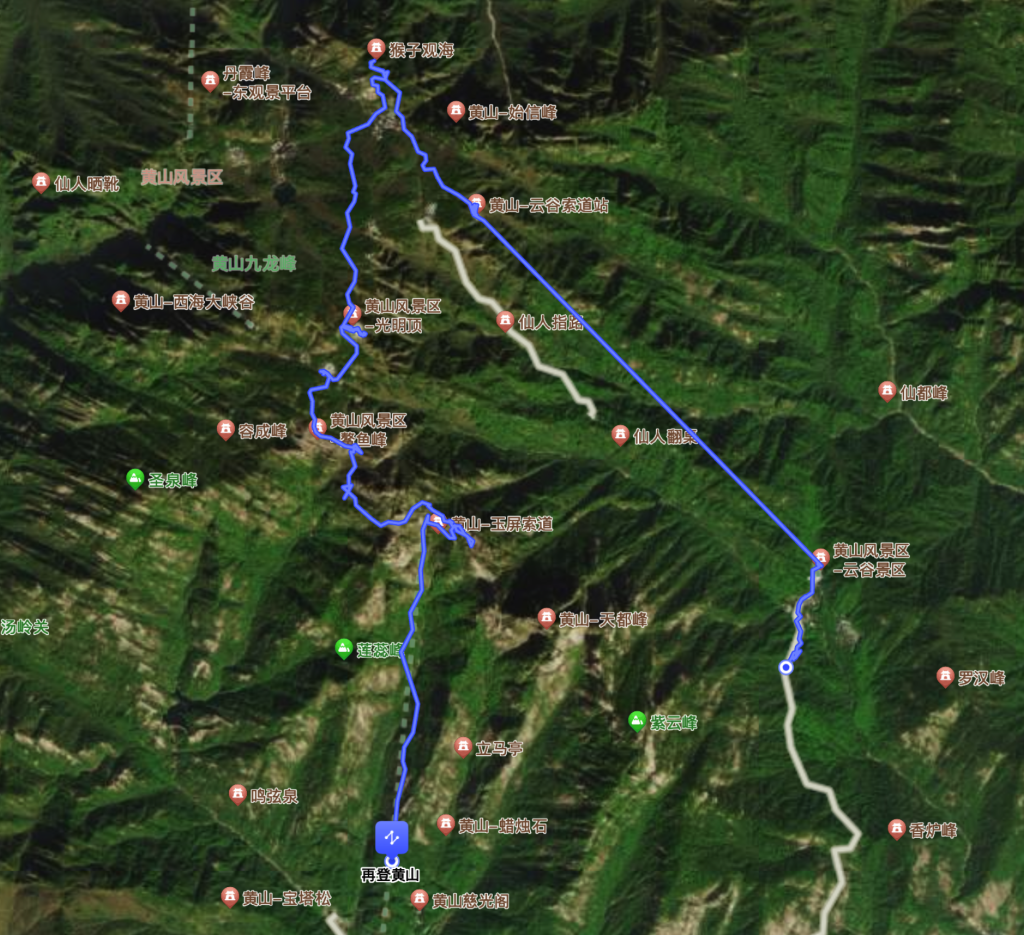
(交互式查看) 从索道上山到最后下山,一共花费了 7 个小时。其中大概有三个半小时,是在吃饭、等人、拍照等,完全没有移动的状态。如果自行安排时间,预留 4~5 小时是比较充裕的,而且体力也不会要求太高。当然,我们没有登最高峰天都峰或莲花峰。
可遇不可求的云海
这次再登黄山,天公作美,看到了可遇不可求的“云海”。黄山以奇石、奇松、云海而闻名。上次来的时候,虽天气不好,但也有幸看到了诸如猴子观海、始信峰等奇石怪峰,也看到了迎客松、黑虎松等奇松。

可遇不可求的黄色云海 
那必须和云海、迎客松一起合个影 再看猴子观海
这次运气不错,视野非常好,远处的“猴子观海”看得非常清晰。


黄山一线天

似乎每个景点都有“一天线” 徽州古镇
在黄山附近,有很多的“徽州”古镇,其中最为有名的大概就是位于的“徽州古镇”。古镇确实也保存的不错,古镇中有很多小巷子,还住着当地的居民。
这一代最为有名就是“许国石坊”。该牌坊已经有400年历史,为万历年间的大学士许国所修。因为牌坊比较牢固、高大所以也躲过十年浩劫,保存非常完整。许国18岁考中秀才,在六次参加乡试时中第一,即为解元。粗略理解,相当于现在的省状元吧。而后参加会试第七名;而后殿试为第一百零七名,为进士三甲[1]。此后,入朝为官,官至吏部尚书、建极殿大学士,《明史》有传。

许国石坊 另外,徽州古镇还保存了一些比较老的建筑。不过应该都是近现代的建筑。

这是一家茶馆 
街角 
小巷子 参考链接
[1] https://zh.wikipedia.org/zh-cn/%E8%AE%B8%E5%9B%BD_(%E6%98%8E%E6%9C%9D)
-
Docker 安装非常简单,几乎一分钟内即可完成安装。
目录
Docker 安装 MySQL 9.1
安装镜像:
docker pull container-registry.oracle.com/mysql/community-server:9.1启动镜像:
docker run --name=mysql91 --restart on-failure -d container-registry.oracle.com/mysql/community-server:9.1查看初始安装时
root账号密码:docker logs mysql91 2>&1 | grep GENERATED登录安装的数据库:
docker exec -it mysql91 mysql -uroot -p好了。这就完成安装了:
# docker exec -it mysql91 mysql -uroot -p Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 10 Server version: 9.1.0 Copyright (c) 2000, 2024, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>修改
root密码:ALTER USER 'root'@'localhost' IDENTIFIED BY 'YOUR-NEW-PASSWORD';详细的步骤与说明可以参考:Basic Steps for MySQL Server Deployment with Docker。
其他的 Docker 相关管理命令
docker start mysql91 # 启动 docker stop mysql91 # 关闭 docker restart mysql91 # 重启 docker rm mysql91 # 删除容器体验 MySQL 9.0/9.1 系列
创建数据库:
mysql> create database orczhou; Query OK, 1 row affected (0.00 sec) mysql> use orczhou Database changed创建一个表,可以用于存储向量,并进行简单的向量计算:
create table vector_t01 ( id int, s_v_01 vector(390), s_v_02 vector(390) ); mysql> create table vector_t01(id int,s_v_01 vector(390),s_v_02 vector(390)); Query OK, 0 rows affected (0.02 sec) mysql> insert into vector_t01 values (1,string_to_vector('[1,2,3]'),string_to_vector('[4,5,6]')); Query OK, 1 row affected (0.00 sec) mysql> select DISTANCE(s_v_01,s_v_02); ERROR 1305 (42000): FUNCTION orczhou.DISTANCE does not exist啥!
FUNCTION DISTANCE does not exist看看文档描述,我下巴掉了一地(参考):
Note
DISTANCE()is available only for users of HeatWave MySQL on OCI; it is not included in MySQL Commercial or Community distributions.没有
search就算了,好不容易有一个DISTANCE,发现还是受限制的…好了,那就体验到这里吧… 期待在后续的版本能够把搜索功能补齐。一定要体验的话,可以自己去Oracle Cloud进行测试。
参考链接
-
标题:Zilliz获Forrester报告全球第一;OB支持向量能力;Azure发布DiskANN,吊打pg_vector;阿里云PG发布内置分析引擎;AWS发布托管Valkey服务
重要更新
Azure发布 PostgreSQL 向量索引扩展
DiskANN,声称在构建HNSW/IVFFlat索引上,速度、精准度都超越pg_vector,并解决了pg_vector长期存在的偶发性返回错误结果的问题 [1] 。阿里云 RDS PostgreSQL 发布AP加速引擎(rds_duckdb)。该引擎提供了列存表和向量化执行能力,显著提升复杂查询的执行速度,且无需修改原始查询语句,从而确保您能够方便且高效地获取结果。当前白名单开放中[7]
OceanBase发布4.3.3版本,支持了向量数据存储与索引功能,这也是4.3版本第一个GA版本[3]。
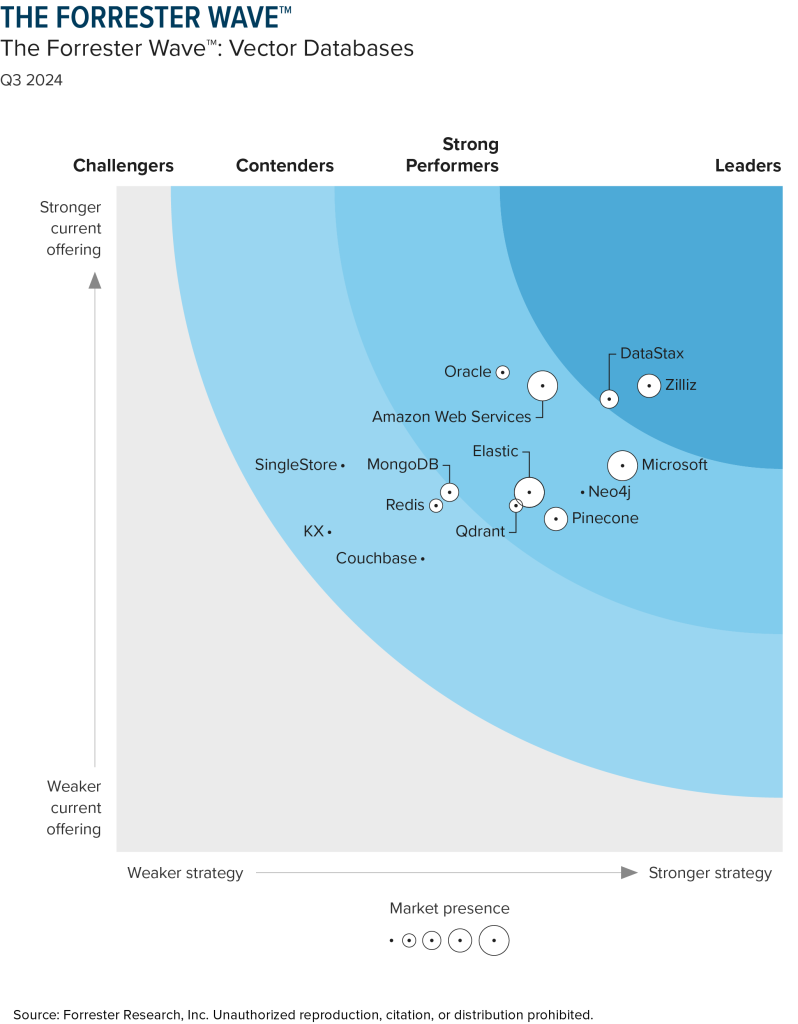
Forrester发布第一份Vector Database的报告(Forrester Wave),Zilliz(产品名:milvus)凭借完整、高效的向量数据处理能力获的第一。后续厂商分别有:DataStax、Microsoft、Amazon、Oracle、Pinecone等[2]。
更新详情
阿里云
- RDS MySQL支持定价详情功能,可以查看各计费项的定价说明和价格。[4]
- RDS PostgreSQL新增支持PostgreSQL 17大版本。[5]
- RDS PostgreSQL高可用系列标准版新增pg.x8.16xlarge.2c(128核 1024GB)独享规格。[6]
- RDS PostgreSQL发布AP加速引擎(rds_duckdb)。该引擎提供了列存表和向量化执行能力,显著提升复杂查询的执行速度[7]
- RDS PostgreSQL 内核版本发布小版本20240830 [8]
- PolarDB Serverless集群支持IMCI列存索引(IMCI)功能 [9]
GCP(谷歌云)
- 创建Cloud SQL支持了证书颁发机构 (CA) 配置功能 [11]
pg_ivm扩展版本 1.9 现已正式发布。此扩展可让您更新物化视图,其中仅计算增量更改并将其应用于视图,而不是从头开始重新计算内容 [12] [13]- “alloydb_scann”扩展程序(以前称为“postgres_scann”)已正式发布(GA),如需详细了解如何存储向量嵌入、创建索引以及调整索引以实现更快的查询性能和更好的召回率,请参阅使用向量。[17]
- 现在,您可以在创建实例后使用“gcloud sql instance patch”命令更新 Cloud SQL for SQL Server 实例的时区。以前,您只能在首次创建实例时为 SQL Server 实例设置自定义时区.[19]
- Cloud SQL for MySQL 8.4 现已正式发布 [24]
- AlloyDB 主实例和备实例上支持公网IP [26]
火山云(字节)
- DBW 数据库审计日志的默认保留时长变更为 30 天,同时新增支持选择保留 180 天、1 年和 3 年。[30]
- 在操作审计页面 DBW 管理员支持查看所有操作行为,DBW 普通用户和非 DBW 系统角色仅支持查看自己的操作行为。[33]
AWS(亚马逊云)
- Aurora Serverless v2 新增支持 256 个 ACU [35]
- Amazon Aurora/RDS 支持控制台到代码 [36]
- Amazon 新增 ElastiCache for Valkey /MemoryDB for Valkey [38] [39]
- Aurora 支持 PostgreSQL 16.4、15.8、14.13、13.16 和 12.20 [50]
- Aurora MySQL 现已支持 RDS 数据 API [51]
腾讯云
- TDSQL-C MySQL 版“只读分析引擎”内核版本更新到1.2404.10.0,主要优化了产品使用的体验和稳定性。支持了 date_sub 函数 [53]
Azure(微软云)
- 托管 PostgreSQL 支持了更多数据库参数的修改 [54]
- 托管 Redis 7.2( Azure Cache for Redis Enterprise)正式发布 [55]
- 托管 PostgreSQL 支持
postgresql_anonymizer插件,更好的保护隐私数据 [56]
参考链接
- [1] https://azure.microsoft.com/en-us/updates/v2/DiskANN-indexing-on-Azure-Database-for-PostgreSQL
- [2] https://mp.weixin.qq.com/s/Sq1GUOTP02QWBOqS0N3A9A
- [3] https://www.oceanbase.com/product/oceanbase-database-rn/releaseNote#V4.3.3
- [4] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/new-features-new-specifications-apsaradb-rds-releases-the-pricing-details-feature
- [5] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/features-of-apsaradb-rds-for-postgresql
- [6] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/primary-apsaradb-rds-for-postgresql-instance-types
- [7] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/use-the-rds-duckdb-extension
- [8] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/release-notes-for-alipg
- [9] https://help.aliyun.comhttps://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/set-the-scale-up-strategy-of-serverless-cluster
- [11] https://cloud.google.com/products#product-launch-stages
- [12] https://cloud.google.com/sql/docs/postgres/extensions
- [13] https://cloud.google.com/sql/docs/postgres/set-maintenance-window
- [17] https://cloud.google.com/alloydb/docs/ai/store-embeddings
- [19] https://cloud.google.com/sql/docs/sqlserver/instance-settings#timezone
- [24] https://cloud.google.com/sql/docs/mysql/create-instance
- [26] https://cloud.google.com/products#product-launch-stages))
- [30] https://www.volcengine.com/docs/6956/155353
- [33] https://www.volcengine.com/docs/6956/1333447
- [35] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-serverless-v2.how-it-works.html#aurora-serverless-v2.how-it-works.capacity
- [36] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Using_C2C.html
- [38] https://aws.amazon.com/about-aws/whats-new/2024/10/amazon-elasticache-valkey
- [39] https://aws.amazon.com/about-aws/whats-new/2024/10/amazon-memorydb-valkey
- [50] https://aws.amazon.com/about-aws/whats-new/2024/09/amazon-aurora-supports-postgresql-new-versions/
- [51] https://aws.amazon.com/about-aws/whats-new/2024/09/amazon-aurora-mysql-rds-data-api/
- [52] https://aws.amazon.com/about-aws/whats-new/2024/09/amazon-timestream-for-influxdb-jakarta-milan-uae-zaragoza/
- [53] https://cloud.tencent.com/document/product/1003/109576
- [54] https://azure.microsoft.com/en-us/updates/v2/performance-management-server-parameters-now-modifiable-on-Azure-Database-for-PostgreSQL
- [55] https://azure.microsoft.com/en-us/updates/v2/Redis-7-2-on-Azure-Cache-for-Redis-Enterprise
- [56] https://azure.microsoft.com/en-us/updates/v2/Azure-Database-for-PostgreSQL-support-for-postgresql-anonymizer