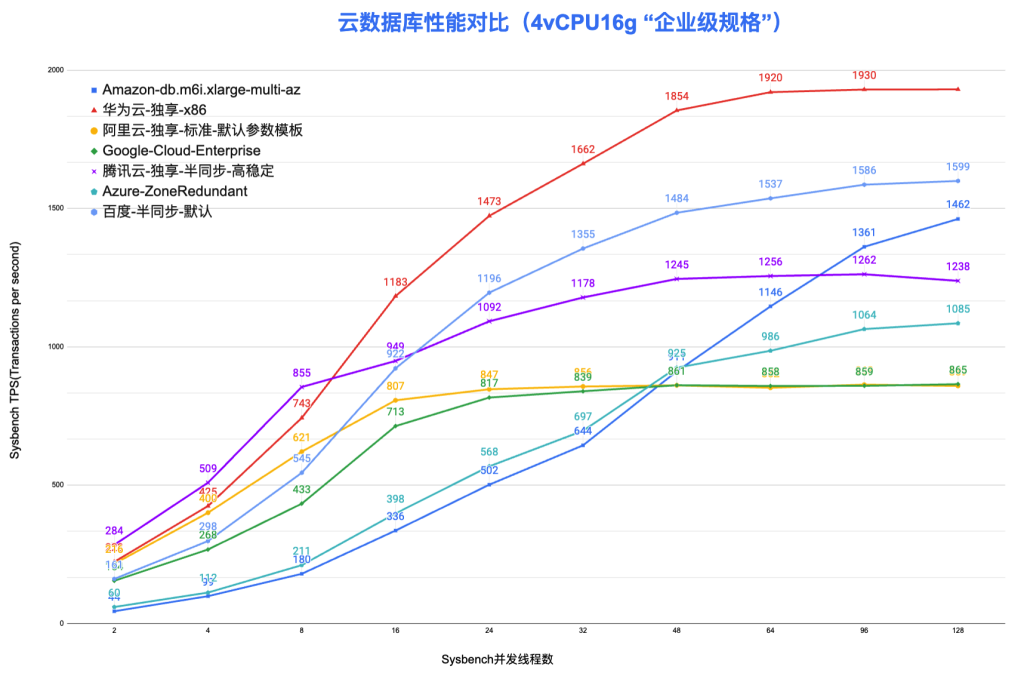
本问是一个系列文章的一部分,该系列较为完整的对各个云厂商的RDS MySQL进行了测试,包括了阿里云、腾讯云、华为云、百度云、AWS、Azure、GCP、Oracle Cloud等,更多参考:云数据库RDS MySQL的性能。
概述
在2018年,AWS首次推出Graviton EC2实例,2020年7月AWS RDS正式支持Graviton 2的实例,就在前两天,在最新的AWS re:Invent大会上,AWS已经推出了第四代Graviton 4实例。现在,AWS的Graviton已经较为成熟,也在大量的企业和应用被广泛使用。AWS官方也宣称使用Graviton 2的RDS实例能够有52%的性价比提升(参考)。这里,来通过标准的Sysbench测试来实测一下,看看实际Graviton 2实例的效果。
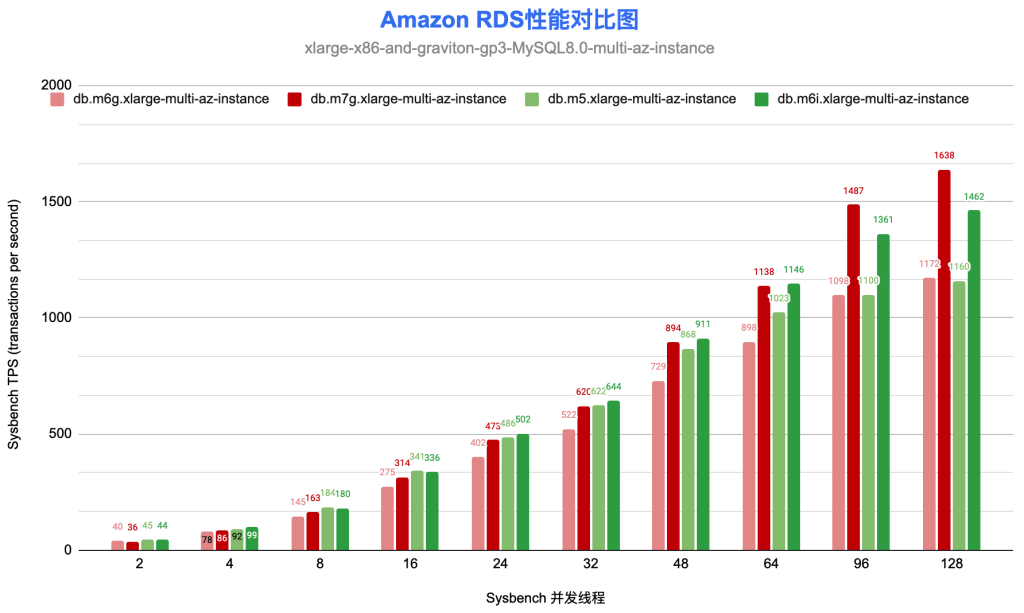
与上次阿里云测试相同,这次依旧是使用了同样的测试工具和场景,对较为常用的4c16gb,即db.m6g.xlarge和db.m5.xlarge实例,进行并发数分别为2 4 8 16 24 32 48 64 96 128的测试。
测试结论
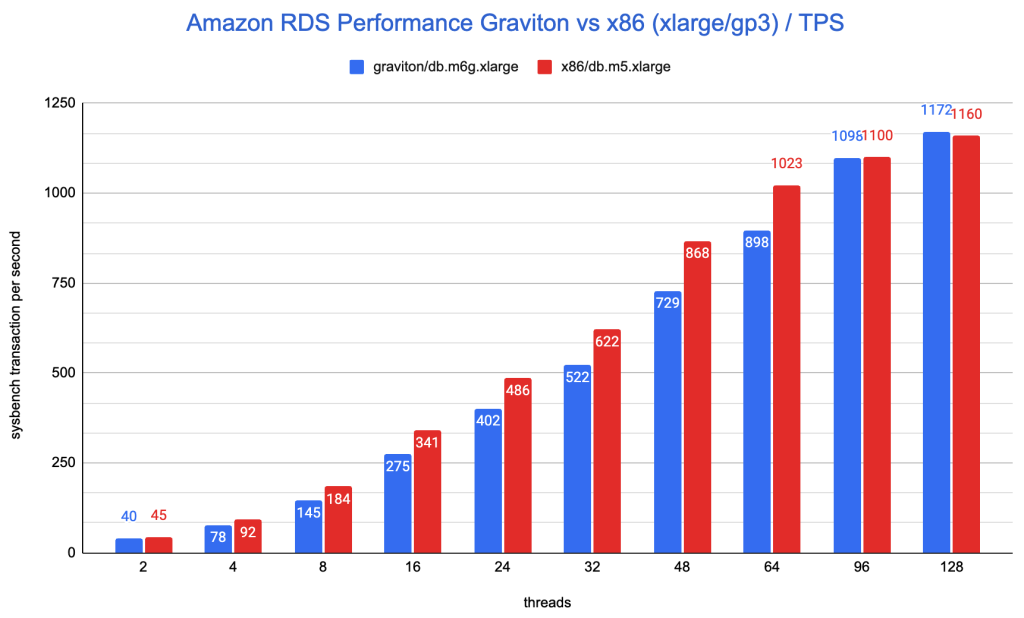
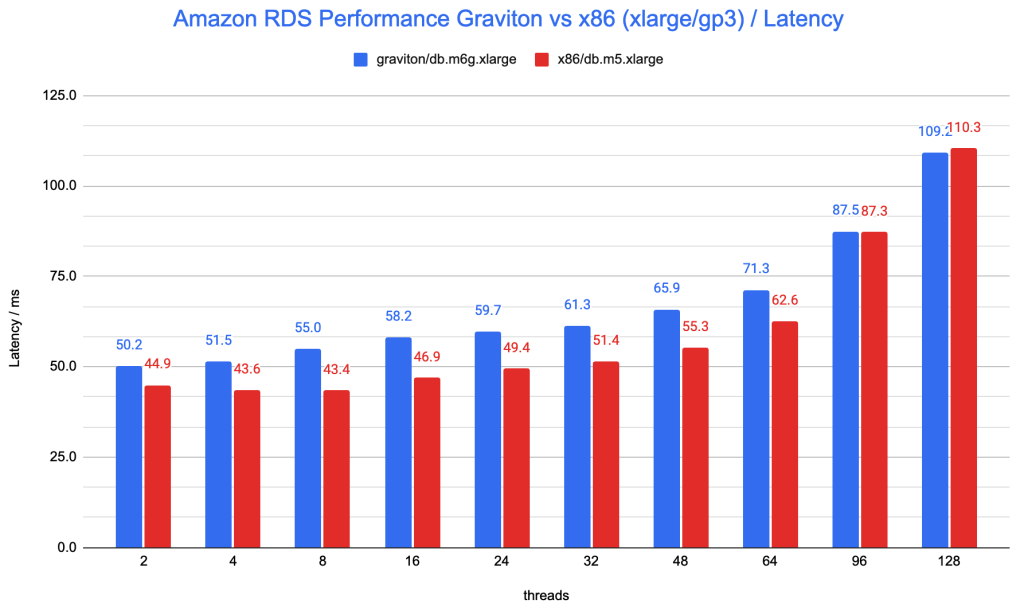
在性能上,平均来看,x86要比Graviton实例性能高约12.7%;x86规格延迟要比Graviton规格低15%。也注意到,在超高并发的情况下(并发超过96时),Graviton实例与x86实例无论是在性能,还是延迟上,是比较接近的,不过,这时候系统压力太大、延迟太高,对实际使用并没有太大的参考价值。
为了更加直观的做性价比的比较,这里选取16并发时的数据进行对比。在16并发下,Graviton实例的TPS是275,db.m6g.xlarge价格是$0.836/小时;x86实例的TPS是341,价格是$0.94/小时。那么每100TPS,Graviton价格是0.304,x86是0.275。所以,在16并发时,相比之下,x86规格的性价比更高,高出Graviton实例10%。这个结果与测试之前预期还是非常不一样的,也与AWS宣称的完全不同。
只有在超高的并发情况下(96/128并发),Graviton实例的吞吐量才与x86接近,这时,Graviton实例才表现出接近10%的性价比优势。但这种高并发在实际场景中并不是常态,所以并没有很强的参考价值。
这个测试结果与预期的差别比较大,所以后来又再做过一次测试,结果与这次基本相同。所以,性能到底怎样,还是最终要自己实际测试,因为宣传的数据,通常都是非常极端的适配该产品的场景,并不是真实的场景。
一下两幅图分别是TPS和平均延迟的对比图:
横坐标是sysbench的并发线程数,纵坐标分别为tps和平均的延迟。
测试模型说明
这里使用了sysbench的读写混合模型(oltp_read_write)进行测试,单表大小为100万,共十个表,单次测试时长为300秒,分别测试了如下的并发度的性能表现:2、4、8、10、12、14、16、24、32。
实例配置与价格
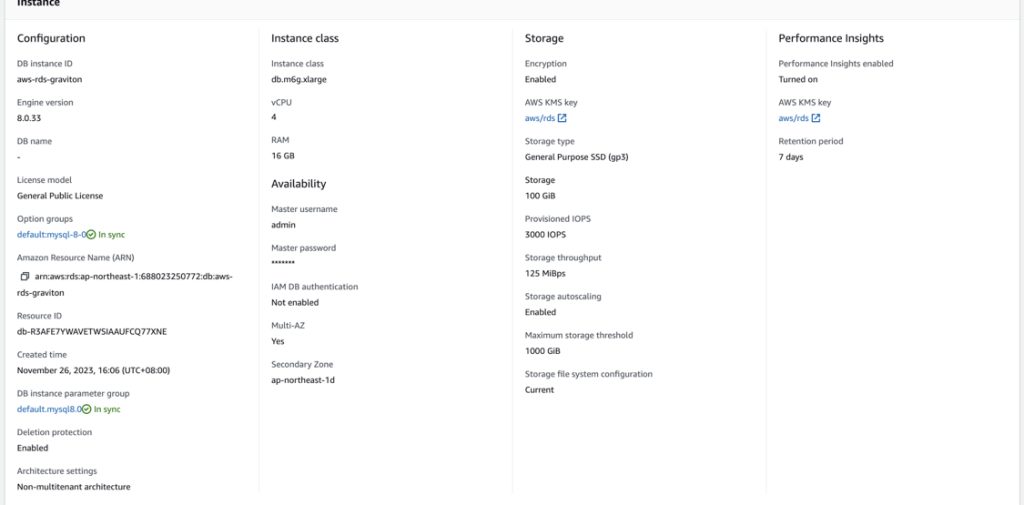
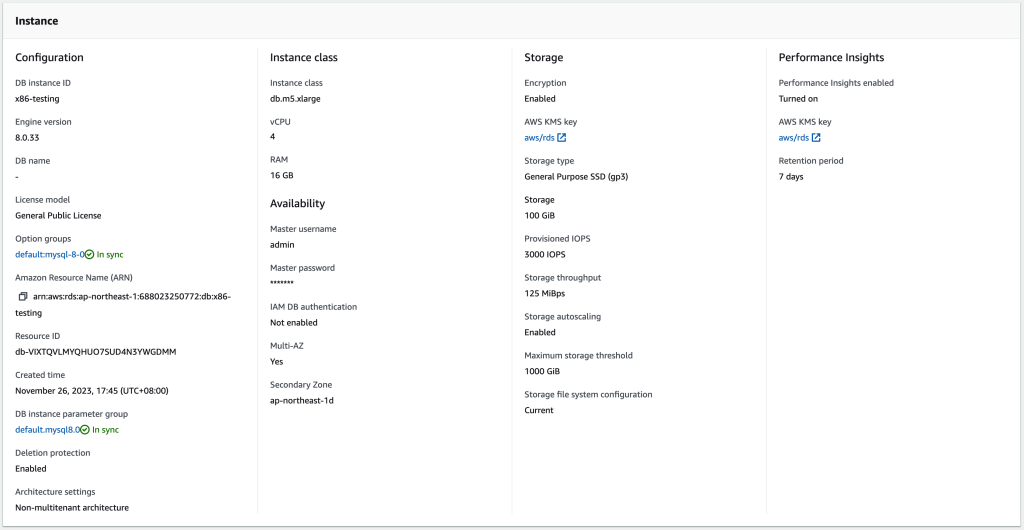
这里选择了较为常用4c16gb的实例进行测试,各个选项尽量选择默认选项,以更加接近的模拟用户实际场景,具体的,版本是AWS默认的8.0.33、多可用区版、存储默认加密、gp3存储、100GB空间、3000 IOPS、Performance Insight也默认开启。完整的选项参考如下:
AWS的价格分为计算节点价格(CPU与内存)、存储价格、IOPS价格,这里仅关注计算节点价格。存储和IOPS对于ARM和x86实例来说,是相同的。这里的选择的是东京地区、多可用区实例的价格,如下:
后续,也还将测试基于 io1(Provisioned IOPS SSD) 存储的RDS。
详细测试数据参考
AWS RDS Graviton(db.m6g.xlarge/gp3/100gb/3000iops/8.0.33)
threads|transactions| queries| time |avg/Latency|95%/Latency
2| 11951| 239020|300.03| 50.21| 55.82
4| 23322| 466440|300.04| 51.45| 57.87
8| 43654| 873080|300.05| 54.98| 65.65
16| 82519| 1650380|300.05| 58.17| 70.55
24| 120541| 2410820|300.06| 59.74| 73.13
32| 156680| 3133600|300.07| 61.28| 74.46
48| 218709| 4374180|300.06| 65.85| 81.48
64| 269430| 5388600|300.08| 71.27| 90.78
96| 329366| 6587320|300.07| 87.45| 121.08
128| 351579| 7031580|300.11| 109.24| 164.45
AWS x86实例(db.m5.xlarge/gp3/100gb/3000iops/8.0.33)
threads|transactions| queries| time |avg/Latency|95%/Latency
2| 13357| 267140|300.03| 44.92| 112.67
4| 27539| 550780|300.03| 43.57| 50.11
8| 55330| 1106600|300.04| 43.38| 51.94
16| 102408| 2048160|300.05| 46.87| 56.84
24| 145718| 2914360|300.05| 49.41| 61.08
32| 186619| 3732380|300.05| 51.44| 63.32
48| 260415| 5208300|300.04| 55.30| 69.29
64| 306939| 6138780|300.08| 62.56| 82.96
96| 330131| 6602620|300.09| 87.25| 123.28
128| 348095| 6961900|300.12| 110.34| 155.80
小结
AWS RDS在发布Graviton 2实例时,曾宣传Graviton 2实例有52%的性价比提升。但是在这里的Sysbench混合读写的测试场景下,反而是x86性价比优势更加明显,16并发是,x86性价比要高出Graviton实例10%。而仅是在超高并发时,Graviton实例性价比才比x86高10%。但是,一般我们不会让4c16的实例,运行在如此高的压力下,所以后面这种情况的参考意义并不强。
虽然AWS曾大量宣传Graviton实例,但是实测下来并没有什么性价比的优势。所以,在数据库应用场景下,使用AWS Graviton实例的必要性,似乎并不高。另外,也注意到,RDS Graviton 3的实例一直都没有推出,也许这是其中的原因之一。
参考